GRPO Training for SQL Query Optimization
Fine-tuned Qwen/Qwen2.5-0.5B-Instruct using GRPO (Group Relative Policy Optimization)
to optimize SQL queries using a DuckDB execution environment.
Overview
This project trains/evaluates SQL optimization with execution-grounded rewards: the environment executes both original and rewritten SQL on real DuckDB data, and scores speedup + correctness + structured diagnostics.
Training curve

If this image ever breaks, the canonical plot is also in the GitHub repo: results/grpo_reward_curve.png .
Training progress (100 episodes)
| Metric | Value |
|---|---|
| Start avg (ep 1–10) | 0.3090 |
| End avg (ep 91–100) | 0.5962 |
| Improvement | +93% |
Final evaluation (per task)
These task scores are aligned to the GitHub repo README (source of truth). Task 5 is the expert scenario, so it is expected to be the lowest — that is not an error.
| Task | Difficulty | Score |
|---|---|---|
| task_1_basic_antipatterns | easy | 0.7500 ✅ |
| task_2_correlated_subqueries | medium | 0.8313 ✅ |
| task_3_wildcard_scan | medium-hard | 0.6563 ✅ |
| task_4_implicit_join | hard | 0.6563 ✅ |
| task_5_window_functions | expert | 0.6500 ✅ |
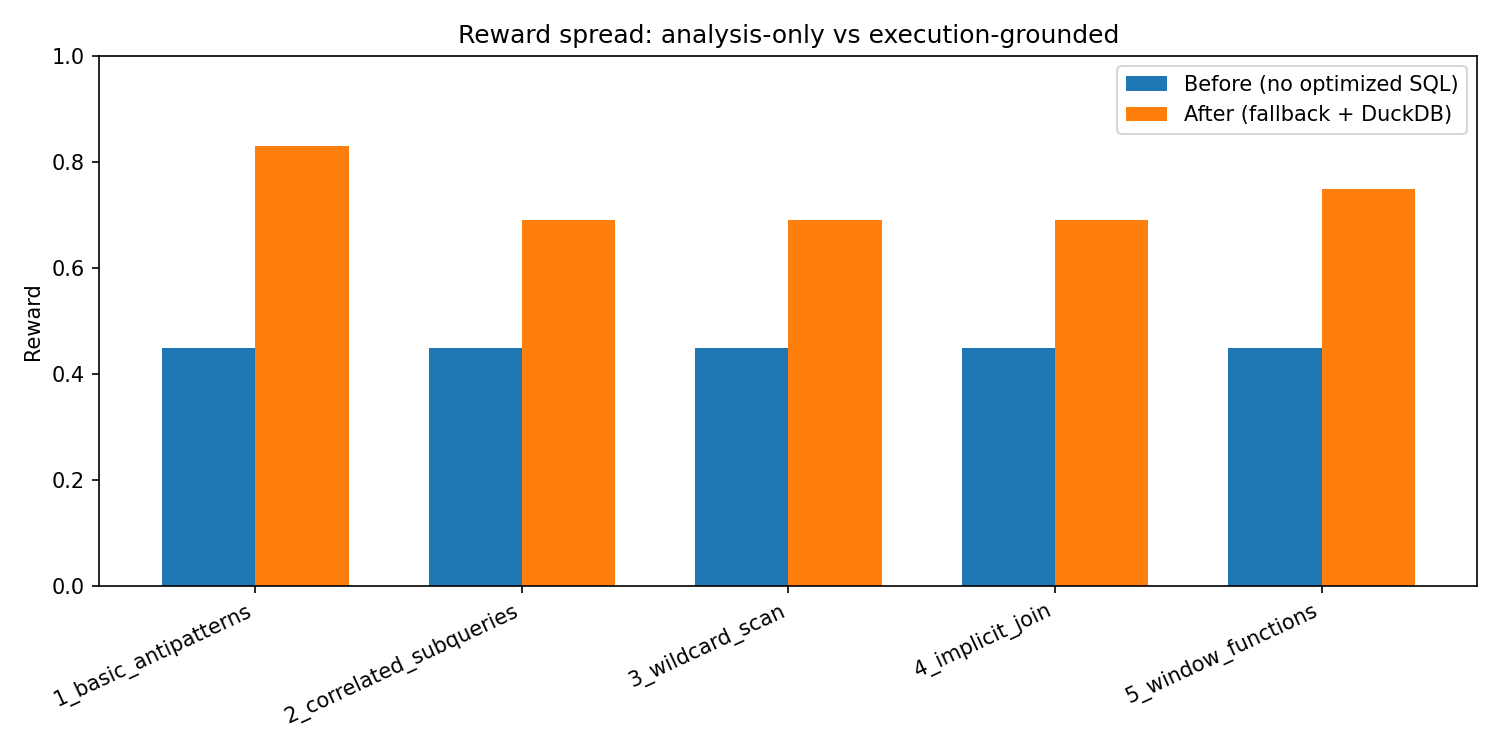
Before / After (environment-only, reproducible)
To avoid hand-wavy baselines, we provide a reproducible before/after contrast in the GitHub repo: “before” = analysis-only (no optimized SQL), “after” = deterministic fallback with a real optimized query. Chart: results/before_after_chart.png
Approach
GRPO setup
- Algorithm: GRPO (Group Relative Policy Optimization)
- Base model: Qwen/Qwen2.5-0.5B-Instruct
- Group size: 4 completions per prompt
- Hardware: Kaggle GPU T4 x2 (see repo links)
Reward components
execution_speedup: measured DuckDB timing ratioresult_correctness: results match check (order-independent for large sets)issue_detection: anti-pattern detection vs ground truth keywordsapproval_correctness,summary_quality,severity_labels